CRUD routes
Overview
Where Mockoon routes are independent and stateless, CRUD routes can generate multiple endpoints to perform CRUD operations (Create, Read, Update, Delete) on data buckets. Data buckets are generated when the server start, their state persisting between calls. It makes them the perfect tool to simulate small databases.
A CRUD endpoint will automatically create a series of routes during runtime, allowing you to perform actions on your data bucket. A typical example is an array of resources (users, invoices, etc.) you can update through a PUT request and see the result in a subsequent GET request.
To create a CRUD route, click on the "CRUD route" entry in the add route menu:
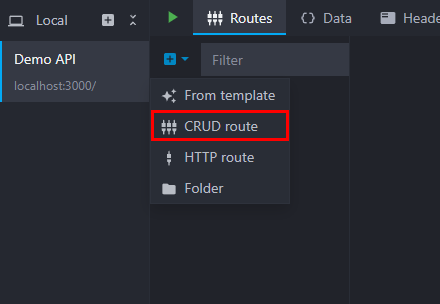
Then, set its path, usually a resource name:

💡 Your path can be more complex, and contains parameters or multiple sections. Remember that this will be the "prefix" of the different endpoints (see below).
Data bucket link
After creating a CRUD endpoint, you need to link it to a data bucket:
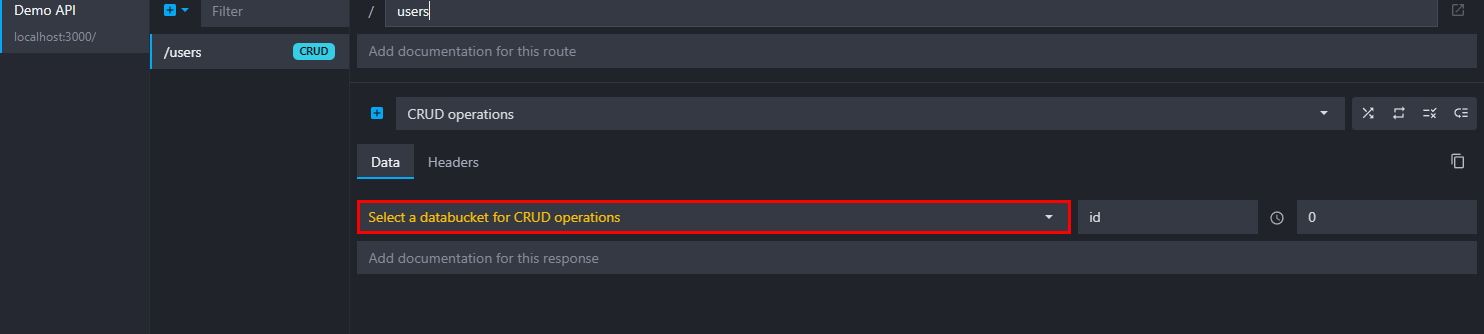
Head over to our data buckets documentation to learn how to create a new data bucket.
Supported content
The CRUD route will work with any content stored in your data bucket: valid JSON in the form of an array of objects, an object, a primitive, etc., or any non-valid JSON. The route behaviors will vary depending on the content stored in the bucket (see table below).
🛠️ Use our JSON validator to check if your content is valid JSON.
Resetting the data bucket content
The data bucket content is generated when the server starts, and its state persists between calls. However, its state will not be saved in the data file, and you can reset it to its initial state by restarting the mock API.
CRUD route differences
When creating a CRUD route, you may notice some differences in the interface, namely:
- The route HTTP method cannot be set and will be handled automatically.
- The status code cannot be changed and will be set automatically while performing operations.
- A fixed and default route response is automatically created and must be linked to a data bucket in order to perform CRUD operations.
Latency and custom headers can still be added. However, an application/json Content-Type will be forced when appropriate.
Also, CRUD routes are still compatible with creating multiple responses and rules. The major difference is that the default route response cannot be set and will always be the first one linked to the data bucket. This response cannot be deleted nor reordered. Aside from these differences everything else still applies.
List of routes and operations
Mockoon will automatically translate a CRUD endpoint to multiple routes allowing for a wide range of behaviors. The system is very flexible and allows for any content, storing and updating primitives to simulate a flag or environment variable system, updating and sorting an array of objects, etc.
Here is a list of the different routes created by a CRUD endpoint and their behavior depending on the content of the linked data bucket (where {path} is the CRUD route path you set when creating the CRUD route, e.g. users):
| Array of objects | Array of primitives (id parameter is acting like an index) | Object, primitive or non-valid JSON | ||
|---|---|---|---|---|
| GET | /{path} | Returns the entire array * | Returns the entire array * | Returns the content |
| GET | /{path}/:id | Returns an object by its id property | Returns an item by its index | Returns the content |
| POST | /{path} | Inserts a new object in the array (autogenerated if not provided) | Inserts a new item in the array | Overwrites the content |
| PUT | /{path} | Replaces the whole data bucket content | Replaces the whole data bucket content | Overwrites the content |
| PUT | /{path}/:id | Performs a full object update by its id (replace) | Replaces the item at index | Overwrites the content |
| PATCH | /{path} | Concatenates the arrays | Concatenates the arrays | Overwrites the content (merge if objects) |
| PATCH | /{path}/:id | Performs a partial object update by its id (merge) | Replaces the item at index | Overwrites the content (merge if objects) |
| DELETE | /{path} | Deletes the data bucket content | Deletes the data bucket content | Deletes the content |
| DELETE | /{path}/:id | Deletes an object by its id | Deletes an item at index | Deletes the content |
* Supports filtering, sorting and pagination
⚠️ Note: You can expect the above results assuming that you are sending the same type of content as the one stored in the data bucket (array ↔ array, object ↔ object, etc.). However, the system is very permissive, and you may push any content in an array, ending up with mixed type contents or replacing content with data of a different type.
Customizing the "id" property
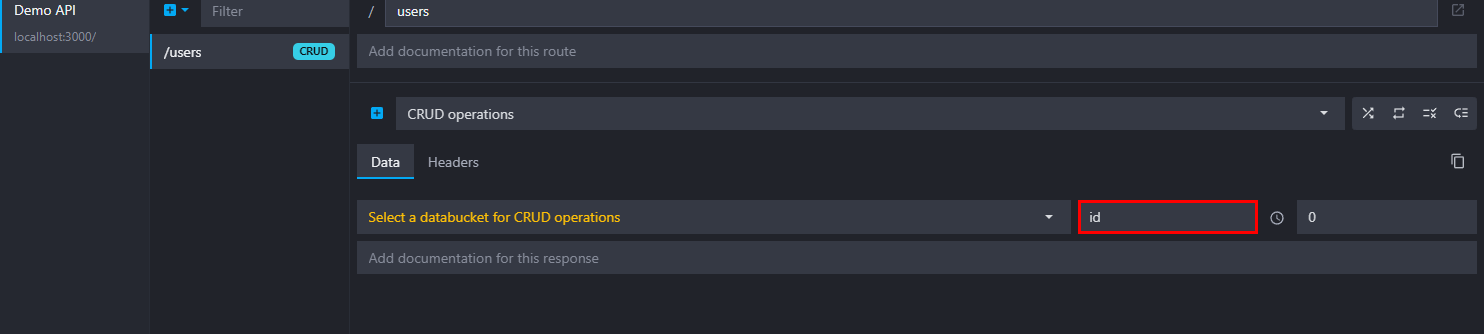
Changing the property name
By default, CRUD endpoints will use the id property to identify objects in an array in all the routes manipulating a single resource (e.g. GET /{path}/:id). However, you can change this property to anything you want, like uuid, custom_id, etc. The crud key also supports the dot notation, allowing you to perform CRUD operations based on nested properties (e.g. data.id).
Autogenerated IDs and numeric IDs
The "id" property is autogenerated during a POST /{path} request if not provided in the request's body. It will be a random UUID v4 string by default. The system will also detect if existing objects in the data bucket have numeric IDs and automatically increment the ID of the inserted object instead of generating a UUID.
💡 The only constraint for using numeric IDs is the presence of at least one object with a numeric ID in the data bucket. If no object has a numeric ID, the system will default to UUIDs.
Overriding a route
You can easily override a CRUD operation route by declaring a regular HTTP route and putting it above the CRUD route (see routes order). This route will intercept the request allowing you to serve custom content for this operation.
Filtering, sorting and pagination on the main GET route
The main GET /path route supports filtering, sorting and pagination when working with an array.
Filtering
To filter an array, you can use query parameters in the form [property]_[operator]. For instance, if you want to filter an array of objects by their status property, you can use:
GET /path?status_eq=success
Currently, the following operators are supported:
| Operator | Description | Example |
|---|---|---|
eq | Filters by equality | status_eq=success |
ne | Filters by inequality | status_ne=error |
gt | Filters by greater | price_gt=10 |
gte | Filters by greater or equal | price_gte=10 |
lt | Filters by lower | price_lt=10 |
lte | Filters by lower or equal | price_lte=10 |
like | Filters by partial match * | name_like=ohn do |
start | Filters properties that start with a value * | name_start=john |
end | Filters properties that end with a value * | name_end=doe |
* Case insensitive
Filters work on every primitive value (strings, numbers, booleans, etc.), so you can filter by true or false values, or even null values:
GET /path?is_active_eq=true
It also works on arrays of primitives, in which case using _[operator] is enough:
GET /path?_gte=10
Moreover, nesting is supported:
GET /[email protected]
The like, start and end operators support regex patterns:
GET /path?user.name_like=^john
GET /path?user.id_like=^(123|456|789)$
Searching
To search an array, you can use the search query parameter. Search is a special kind of filter that will look for a partial match in any values (with nesting) in the array. For instance, if you want to search for john in an array of users, you can use:
GET /path?search=john
Searching also works on arrays of primitives (strings, numbers, etc.)
Sorting
To sort an array, you can use the sort and order query parameters. You can sort by any property in the objects (strings or numbers) and order by either ascending or descending order:
GET /path?sort=name&order=desc
Sorting is also working on arrays of primitives (strings, numbers, etc.), in which case, the presence of the sort parameter is enough:
GET /path?sort&order=asc
Pagination
To paginate an array, you can use the page and limit query parameters. If you omit the limit parameter, it will default to 10 per page. If you omit the page parameter, it will show you the first x items.
Examples:
-
second set of 25 items:
GET /path?page=2&limit=25 -
first 50 items:
GET /path?limit=50 -
second set of 10 items:
GET /path?page=2
Filtering, sorting and pagination can work together and are applied in the order: filtering / searching, sorting, pagination.
GET /path?search=j&[email protected]&sort=name&page=2&limit=25
Meta data
When using CRUD endpoints, you can access meta data about the data bucket content through response headers:
X-Total-Count: total number of items in the bucketX-Filtered-Count: number of items after filtering (not taking into account pagination)